
こんにちは。本記事では、PythonのライブラリであるPandasのデータフレームでの最大値を持つ行名・列名の取得について取り扱います。
特に最大値がデーアフレーム内のどこにあるかを特定させたい場合などに、使用することが多いイメージです。私もその形で使用しました。
それでは早速コードを見ていきましょう。
該当コード
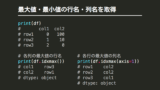
import pandas as pd
df = pd.read_csv('data.csv')列内の最大値を持つ行名を取得する
max_row_name = df["column1"].idxmax()列内の最小値を持つ行名を取得する
min_row_name = df["column1"].idxminある1行を見た時に、最大値を持つ列名を取得する
# 同じ値になる
max_column_name = df.idxmax(axis=1)
max_column_name = df.idxmax(axis="columns")解説

このPythonのDataFrameで使用できるidxmaxですが、どのような場面で使用するかというと、列のスケールが揃っている場合に、比較して最大値となる列を取得したいなどの場合に使用することがあるかと思います。
また、0~1の評価値をとる指数が複数あったとして、行名に処理の名前などが格納されていて、各行の処理結果が列に格納されているとき、idxmaxは非常に役に立ちます。
例えば、列のある値を複数使用して、処理にかけて複数の評価値を用いて総合的に見て評価値のバランスが良く高い数値の組み合わせを使用したい場合に使えます。私はそんな感じで使ってます。
ある値の組み合わせを文字列結合して行名にすることで、組み合わせに対する評価値を取得することができます。
参照サイト
まずは公式ドキュメントをご参照ください。

安定のnkmk
まとめ
以上となります。
シンプルに行名だけを取得する状況はそこまで多くないと思いますが、解説を読んでいただければ使用状況がご理解できたかと思います。
システム開発的な側面よりも、データサイエンス的な側面(探索的)な場面で役に立つと思います。特に最大値の行名が知りたい状況なんて特にそうですよね。
ということで、PythonのライブラリPandasのデータフレームに対して使用できる.idxmax()について紹介しました。.idxmax()は列内の最大値を持つ行名を取得することができます。
ぜひ使ってみてください!
サイト内関連記事






転職・スキルアップはこちらからどうぞ
- 転職のリクルートエージェント:転職実績No.1
国内最大級の転職サイトです。まずは登録!
- 若手ハイクラス転職 VIEW:若手からの支持がアツい 高待遇案件多数!一見の価値有りです
- 未経験ならIT求人ナビ:未経験フルサポート
未経験支援が充実しています!
- 受講者国内最大級:オンライン資格講座スタディング
まずはここから探すのがオススメです
- エンジニアのスキルアップに特化:テックアカデミー プログラミングに興味ありなら
- オンライン完結型スクール:DMM WEBCAMP PRO 転職型スクールNo.1 オススメです



コメント