
BigQueryのデータはBigQuery内で処理をして、Pythonでの加工はPythonで行っていくのがより良いかと思います。しかし、状況よってはRDBのデータとPythonでの処理を一箇所で行いたいこともあるかと思います。
今回はそんな要望に対応できるように、JupyterNotebookで完結できるような処理をご紹介いたします。
処理概要
- pandas-gbqをpip install
- BigQueryに投げるSQL文を文字列で生成
- pd.read_gbq()でBigQueryにリクエストを送信
- データがデータフレームで返ってくる
なんと簡単なこと!
ただし、初めての処理の場合は認証の作業が入りますので、そこだけほんのちょっと面倒かもしれません。が、これもいうほど面倒ではないので、実質ほぼ面倒ゼロですね。
コード
!pip install pandas pandas-gbq
# ノートブックでの作業ですので、pipコマンドの前に"!"をつけるのをお忘れなく!今回はノートブック上での完結を目指しますので、ノートブックでpipコマンドも完遂させます。とはいえこの部分は別にこだわらなくも全然平気だと思います。
import pandas as pd
sql_table_name = "¥
SELECT ¥
table_name ¥
FROM {データセット名}.INFORMATION_SHEMA.TABLES ¥
WHERE table_name LIKE '%_table' ¥
AND ¥
NOT table_name LIKE '%_backup'"
project_id = '{プロジェクトID}'
df_table_name = pd.read_gbq(sql_table_name, project_id=project_id, dialect='standard')上記がBigQueryからテーブルデータを参照するスクリプトの一例です。
今回は、データセット内の各種情報が保存されている「インフォメーションスキーマ」から情報を抽出しています。「インフォメーションスキーマ」は明示的に確認することはないですが、同じスクリプトの中で情報を取得することができるので、処理の中に組み込ませることができます。
私が書いたことのある一例としては、上記の通り、「_table」というテーブル名で、かつ「_backup」というテーブル名ではない、テーブル名のテーブルを取得するというもの。
これをどのように使ったかというと、該当するテーブル名一覧をリスト化して、プルダウンからスクリプトの実行者に選択させるという処理を書きました。(ipywidgetsを使用しました。)
注釈
- sql_table_name
- BigQueryに送るSQLが文字列で格納される
- FROM {データセット名}.~~
- データセットの名前を書く
- BigQuery上でSQLを書くときと同じノリ
- project_id = ‘{プロジェクトID}’
- プロジェクトIDを書く
- BigQueryの中で一番大きい単位の枠組み(だと思う)
参照したサイト


認証作業(初回実施の時に発生)
この部分は一回クリアすればあとはほぼ実行されないと思いますので、初回だけ参考にしていただければと思います。
手順①
サンプルコードなどを実行すると、以下のような要求をされますので、URLからアクセスし、以下の手順で認証コードを取得していきます。
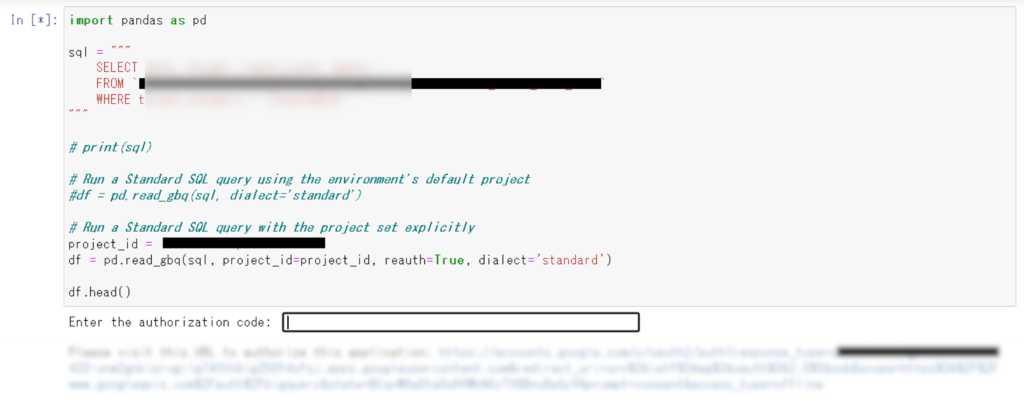
手順②
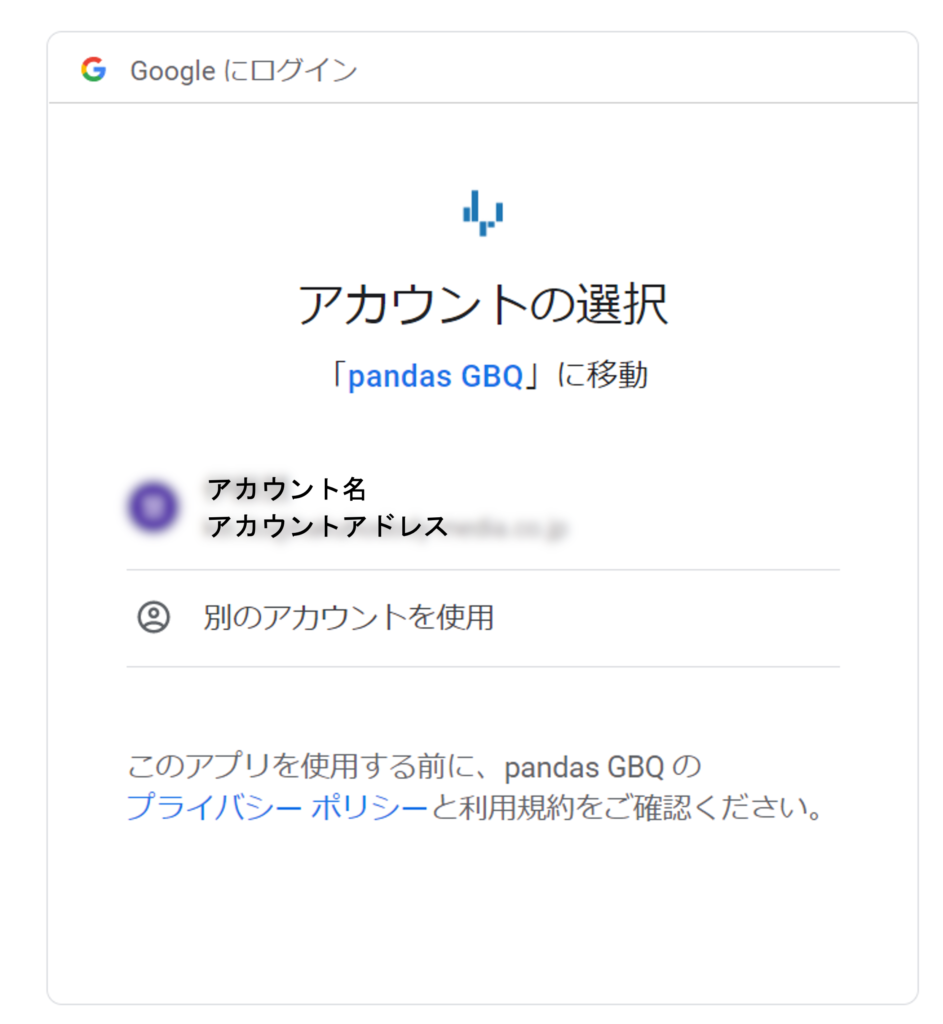
URLからアクセスすると次のような形で認証を要求されます。アクセスを許可するアカウントを選択してください
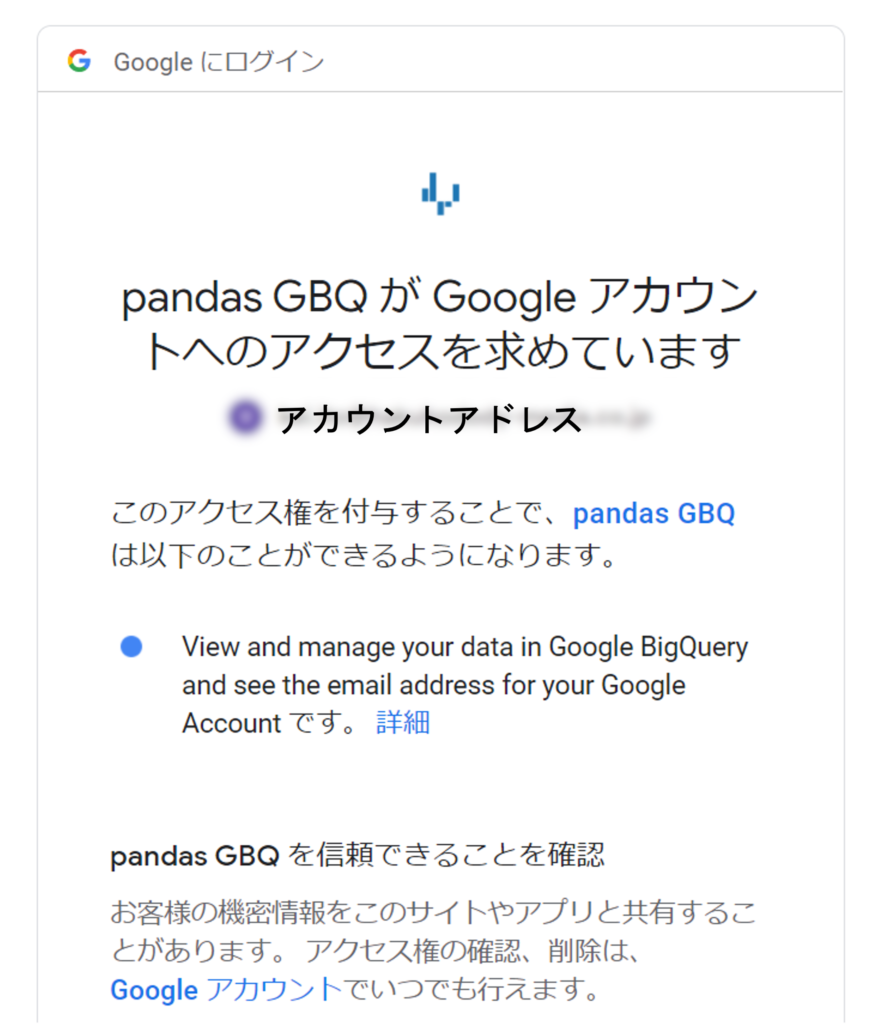
アカウントを選択して進むと、上記のような確認をされますので、続行を押して先に進んでください。(ただし、選択しているアカウントなどが正しいかどうかはしっかりと確認してくださいね。)
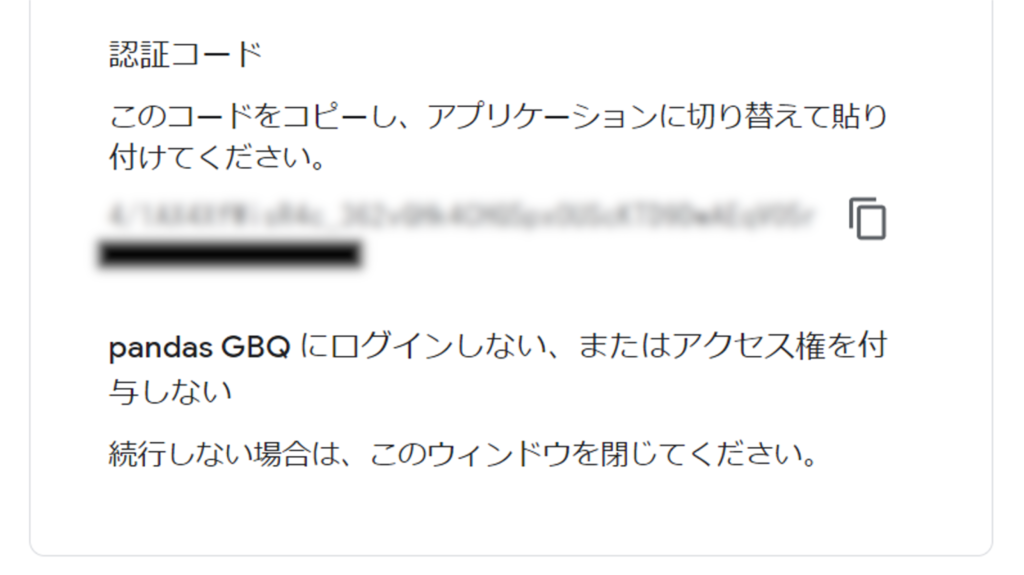
認証コードが出てきますので、こちらをコピーしてください。
手順③
先程コピーした認証コードを、入力ボックスのなかにペースト貼り付けて、エンターを押してください。
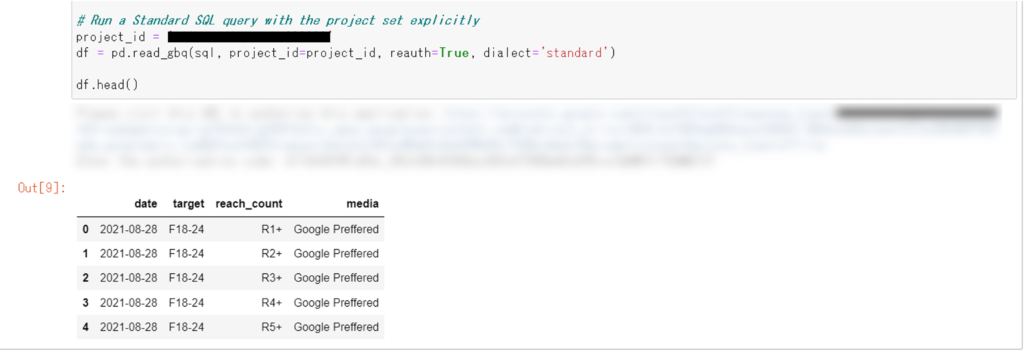
すると認証がクリアされ、SQLのリクエストが送られて結果をデータフレームで返してくれます。




コメント