
本記事はPythonのライブラリである「Pandas」のデータフレームのデータ抽出について取り扱います。SQLのように、テーブル上のデータに条件をかけてその条件に該当する行を抽出するにはどうしたら良いか解説いたします。
該当コード
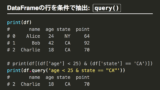
まずはシンプルにコードをご確認ください。
import pandas as pd
# データの読み込み
df = pd.read_csv('data.csv')シンプルな抽出
df_query = df.query('Col_1 > 0')文字列の条件による抽出
df_query = df.query('Col_2 == "文字列は外側と違う引用符で囲む"')否定・不一致の場合
# 否定
df_query_hitei = df.query('not Col_3 == 0')
# 不一致
df_query_fuicchi = df.query('Col_4 != 0')インデックス(行名)に対しても可能
df_query_index = df.query('index >= 100')解説

最大の注意点は、文字列で入れてあげるというところです。列名だけを文字列で表現することも多いかと思いますので、注意していください。列名に続く演算子、条件も同じ文字列の中に入れてください。文字列なので、「f文字列」も、場合によっては、使いやすくなるかもですね。
数値の条件では、比較演算子などを使ってシンプルに抽出することが可能です。
文字列の条件では、文字列を外側の引用符と異なるもので囲む必要があります。同じ引用符で囲ってしまうとquery()内で文字列として認識することができなくなってしまうので注意してください。
否定・不一致による条件抽出も可能です。ここら辺は直感にも反しないと思いますので、特段補足はいたしません。否定は「not」、不一致は「!=」でOKです。
最後にインデックスを条件にかけて抽出することも可能です。これは使ったことがありませんが、意外に便利かもと思うところです。インデックスをうまく使いこなせているのであれば、この方法で条件抽出しても良いかもですね!
参照サイト
安定のnkmk
公式リファレンス

まとめ
データフレームに対して、列に条件をかけてSQLのようにデータ抽出をしてみました。元も子もないですが、データ抽出はSQLの方が得意です。特段の理由がないのであれば、取り扱うデータはすでに条件によってデータ抽出できている方が望ましいです。
とはいえ、扱うデータによっては、この処理の中で条件によるデータ抽出をする必要があるということもあると思います。私も実務で経験しています。どうしても処理が重くなってしまうので避けるべきですが、しょうがないですね。
以上、【データフレームの列に条件をかけてデータ抽出する】でした。
上級者の方で、気になる点などございましたらご指摘いただけると大変助かります。よろしくお願いいたします。
サイト内関連記事







転職・スキルアップはこちらからどうぞ
- 転職のリクルートエージェント:転職実績No.1
国内最大級の転職サイトです。まずは登録!
- 若手ハイクラス転職 VIEW:若手からの支持がアツい 高待遇案件多数!一見の価値有りです
- 未経験ならIT求人ナビ:未経験フルサポート
未経験支援が充実しています!
- 受講者国内最大級:オンライン資格講座スタディング
まずはここから探すのがオススメです
- エンジニアのスキルアップに特化:テックアカデミー プログラミングに興味ありなら
- オンライン完結型スクール:DMM WEBCAMP PRO 転職型スクールNo.1 オススメです



コメント