
本記事は、PythonのライブラリPandasのデータフレームの列の分割について解説した記事になります。データフレームの1列を分割するようなシチュエーションは、だいたい前処理の過程でしょう。例えばメールアドレスからドメイン数を集計したかったりなどでしょうか。
私の場合は、ユーザーエージェントをparseして文字列を取り出して上で分割するような使い方をデータサイエンティストの実務で行いました。
それでは早速コードの方を見ていきましょう。
該当コード
まずは前提を整えます。
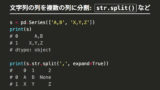
import pandas as pd
df = pd.read_csv('data.csv')まずはシンプルに分割する方法
# @で分割する場合
df["column"].str.split("@")列を分割して、それをデータフレームの列にする場合
df_split = df["column"].str.split("@", expand=True)元のデータフレームを活かす方法
df_concat = pd.concat([df, df["column"].str.split("@", expand=True)], axis=1)解説

ざっくり以上となります。
上記紹介しているコードでは注意点などがありますので、ご注意ください。
- シンプルな分割方法
こちらはシンプルな活用方法です。ただしこの方法だと元のオブジェクト(データフレーム)は何も変わらないので注意が必要です。
しっかりと分割ができているかを確認するなどのシチュエーションであればうまく活用できそうですね。
- データフレームの列にする方法
(exoand=True)と指定することで、分割して列に「拡張」することができます。分割してそのまま列にできます。これはおそらく分割した後にやりたい処理そのものかと思います。これを自然とできるようになれると良いかと思います。
- 元のデータフレームを活かす方法
この方法は列を分割し、元のデータフレームと結合する方法です。分割する列だけでできているデータフレームを扱うことはないと思います。元々のデータフレームを活かしつつ、列を分割して前処理の一つとするような流れの中で使用されます。データフレームの結合でもあるので、うまく活用してください。
さらに注意点があります。
分割に使用する文字列(例でいう「@」のこと)が、分割したい列の要素の中に複数ある場合、あるだけ分割されてしまいます。
さらに、列の中で分割する文字列の数が異なる場合、変な感じで列が分割されます。間違いなく思っていた通りの処理がされないので、気になる方は試してみてください。
分割する文字列の中に同じ個数あるかどうか、イレギュラーが潜んでいないかよく確かめましょう。
加えて、分割した後の列名はリセットされます。列名の変更はこちらをご参照ください。

参照サイト
公式ドキュメント

安定のnkmk
まとめ
以上となります。
いかがでしたでしょうか。ただ分割したいだけでも、色々と注意点があったりでめんどいですよね。前処理は小さなことを丁寧に一つ一つやっていく必要があるので根気強さが大事ですね。
上記を参照して、どんどん列を分割していってください。列の分割はメールアドレスの分割や住所の分割だったり、Webアクセスで活用されるユーザーエージェント(user agent)などの取り扱いなどで活用されることが、私の経験上多いです。注意点に気をつけながら使ってみてください。
サイト内関連記事





その他の技術系記事も書いています









転職・スキルアップはこちらからどうぞ
- 転職のリクルートエージェント:転職実績No.1
国内最大級の転職サイトです。まずは登録!
- 若手ハイクラス転職 VIEW:若手からの支持がアツい 高待遇案件多数!一見の価値有りです
- 未経験ならIT求人ナビ:未経験フルサポート
未経験支援が充実しています!
- 受講者国内最大級:オンライン資格講座スタディング
まずはここから探すのがオススメです
- エンジニアのスキルアップに特化:テックアカデミー プログラミングに興味ありなら
- オンライン完結型スクール:DMM WEBCAMP PRO 転職型スクールNo.1 オススメです



コメント