
先日YouTubeでPandasデータフレームのto_csvメソッドは最遅方法であることを解説してくれた動画を拝見しました。自分でも実行してみたら、まさにその通りでびっくりでしたので、記事にまとめます。
データの前処理を一時保存したり、処理の経過を見られるようにするために当たり前のようにto_csvを使用していましたが、保存する容量や処理速度を意識するとto_csvではどうにも追いつかないことがあります。その時にto_parquetがおすすめです。注意点もあるので最後までご覧ください。
該当コード
下準備
import pandas as pd
df_csv = pd.read_csv('data.csv')
df_parquet = pd.read_parquet('data.parquet')基本的な使い方のみ紹介
df_csv.to_parquet('data.parquet')
df_parquet.to_csv('data.csv')
# df_csvもdf_parquetもデータフレームオブジェクトのため、csv形式でもparquet形式でも保存できる
# 使い慣れた「csv」の部分を「parquet」に変えるだけ実際に動かしてみる
まずは大きめのcsvを読み込む
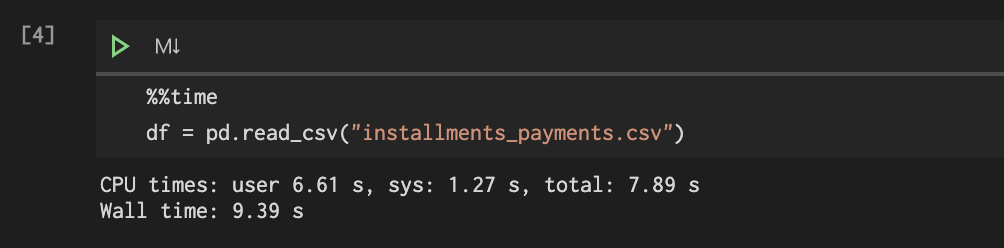
データフレームとして読み込んだ大きめのcsvをcsvとparquetで保存して比較する
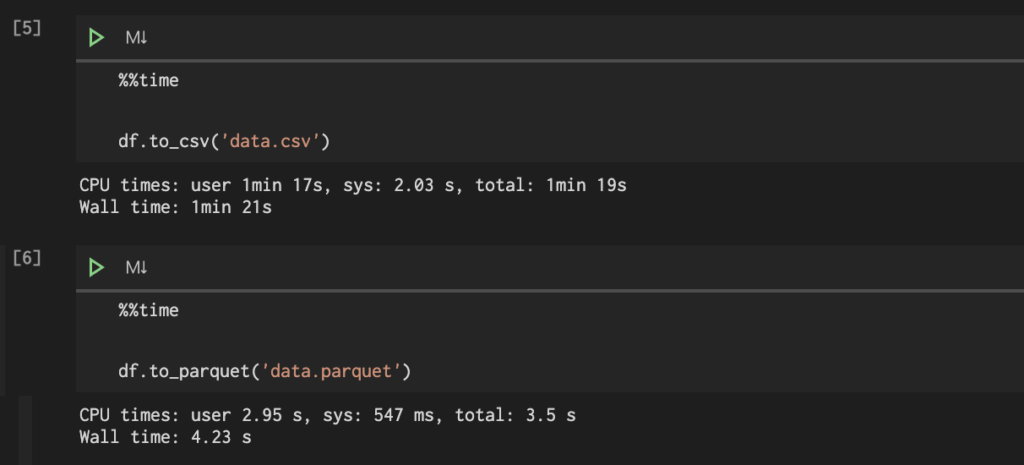
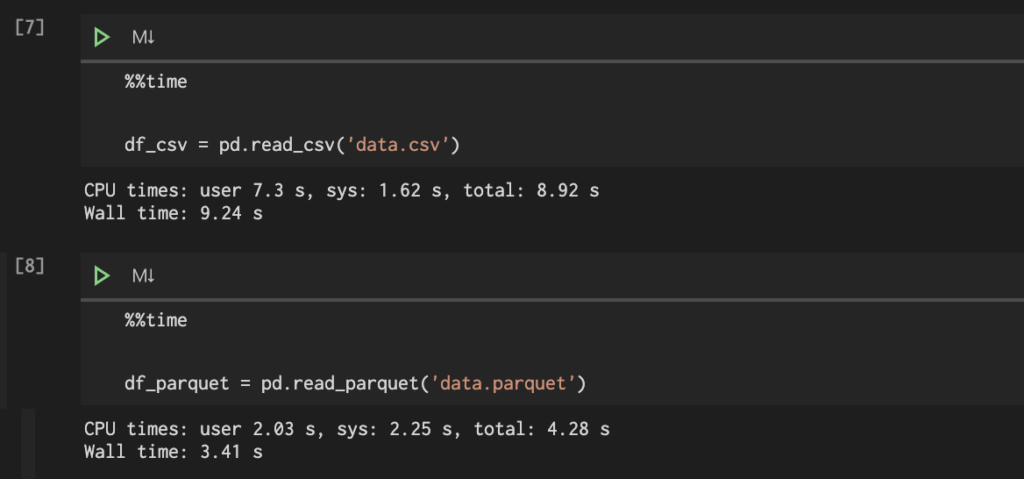
保存したcsvとparquetをデータフレームとして読み込んで比較する
最後に保存しているデータ容量を比較

参照サイト
公式ドキュメント

まとめ

基本的には、「read_csv」「to_csv」と使い方は変わりません。index=Falseなども使用することができます。
そのため、特段の理由がない限り「parquetファイル」で保存とロードをするのが良い手のように感じました。
しかし落とし穴があります。それはparquetファイルはUIで開けません。csvだとよくエクセルで開いて中身を軽く確認するなんてことができますが、parquetファイルはそれができないので要注意です。
UIで確認ができないので、Pythonで動かして確認する必要があります。その点で、プログラミングができないと確認できないのがデメリットですね。
確認する用途としてはあまり使用しにくい中間テーブルなどをparquetファイルで出し入れし、集計結果などをcsvで非エンジニアにも扱いやすいようにするというのがベターかと思います。
そんな感じで使えることを理解しておきましょう!
サイト内関連記事





その他の技術系記事も書いています









転職・スキルアップはこちらからどうぞ
- 転職のリクルートエージェント:転職実績No.1
国内最大級の転職サイトです。まずは登録!
- 若手ハイクラス転職 VIEW:若手からの支持がアツい 高待遇案件多数!一見の価値有りです
- 未経験ならIT求人ナビ:未経験フルサポート
未経験支援が充実しています!
- 受講者国内最大級:オンライン資格講座スタディング
まずはここから探すのがオススメです
- エンジニアのスキルアップに特化:テックアカデミー プログラミングに興味ありなら
- オンライン完結型スクール:DMM WEBCAMP PRO 転職型スクールNo.1 オススメです



コメント