
Pythonでは、内包表記(comprehension)という便利な機能を活用することができます。これは一連の要素を処理し、新しいリスト、辞書、集合を生成するための簡潔で強力な方法です。本記事では、内包表記の基本的な使い方から、その応用方法を解説いたします。ぜひご活用ください。
リスト内包表記
Pythonの内包表記の中でも最も一般的に使用されるのがリスト内包表記です。以下にその基本形を示します。
[expression for item in iterable]この構造は、iterableの各アイテムに対してexpressionを取り出し、結果を新しいリストに追加します。たとえば、0から9までの整数のリストを取得するには次のようにします。
numbers = [i for i in range(10)]
print(numbers) # Output: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]リスト内包表記には条件を追加することも可能です。これにより、特定の条件を満たす要素だけを新しいリストに含めることができます。
numbers = [i for i in range(10) if i % 2 == 0]
print(numbers) # Output: [0, 2, 4, 6, 8]この例では、range(10)の各要素に対して、その要素が偶数である場合にのみ新しいリストに追加します。

辞書内包表記
辞書内包表記はリスト内包表記と非常に似ていますが、キーと値のペアを生成します。その基本形は次の通りです。
{key_expression: value_expression for item in iterable}たとえば、各英小文字とそのUnicodeコードポイントをマッピングした辞書を作成するには、次のようにします。
import string
letter_mapping = {letter: ord(letter) for letter in string.ascii_lowercase}
print(letter_mapping) # Output: {'a': 97, 'b': 98, 'c': 99, ..., 'z': 122}辞書内包表記でも、リスト内包表記と同様に条件を追加することができます。
集合内包表記
集合内包表記も可能で、これにより独自の集合を生成できます。その基本形は次の通りです。
{expression for item in iterable}たとえば、リストから重複する要素を取り除いた場合は、次のようにします。
numbers = [1, 1, 2, 3, 4, 4, 5, 5]
unique_numbers = {n for n in numbers}
print(unique_numbers) # Output: {1, 2, 3, 4, 5}この集合内包表記は、numbersリストの各要素を通過し、重複なしでその要素を集合に追加します。
内包表記のネスト
内包表記はネストすることも可能です。これは、内包表記の中に別の内包表記を含めることを意味します。例えば、2次元のリスト(リストのリスト)を1次元に平坦化することができます。
nested_lists = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
flattened = [number for sublist in nested_lists for number in sublist]
print(flattened) # Output: [1, 2, 3, 4, 5, 6, 7, 8, 9]この例では、最初のforループが外側のリストを通過し、次のforループが各内部リストを通過します。これにより、2次元リストが1次元リストに平坦化されます。
ジェネレータ内包表記
最後に、ジェネレータ内包表記について触れておきましょう。これはリスト内包表記と似ていますが、新しいリストを生成する代わりに、ジェネレータオブジェクトを生成します。ジェネレータは遅延評価されるため、大量のデータを処理する際にメモリを節約できます。
numbers = (i for i in range(10))
print(numbers) # Output: <generator object <genexpr> at 0x7f0c6c7a8200>ここでは、()を使用してジェネレータ内包表記を作成しています。numbersはジェネレータオブジェクトなので、要素は必要になるまで計算されません。これを具体的に示すために、next()関数を使ってジェネレータから要素を一つずつ取り出してみましょう。
print(next(numbers)) # Output: 0
print(next(numbers)) # Output: 1内包表記とfor文の実行時間の違い
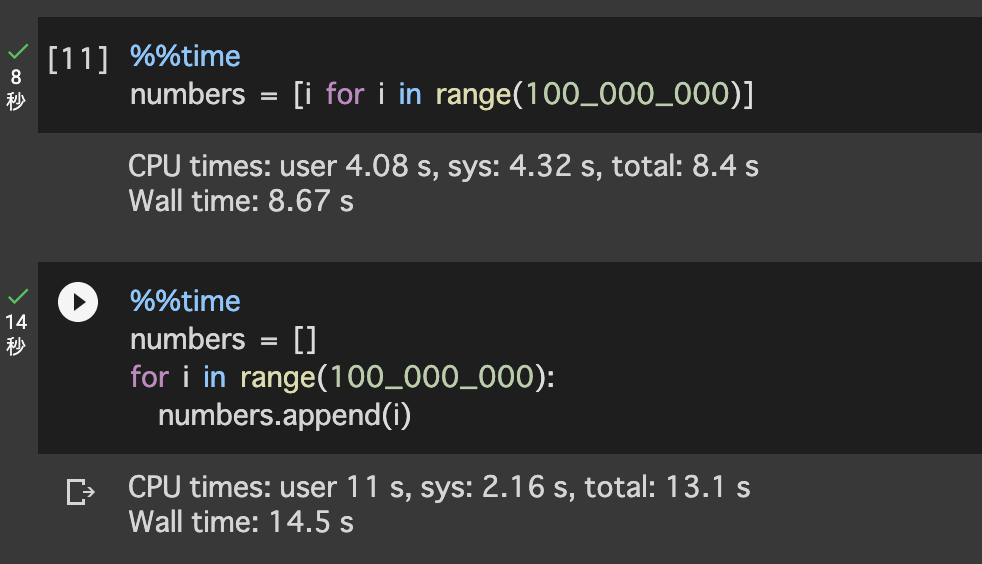
ご覧の通りの違いがありました。内包表記の方が実行時間は短いことがわかります。この違いは`append`メソッドを呼び出す必要があったりするので、このような違いが出てきているようです。処理の高速化や軽量化をしたい場合などは、内包表記の方が良いコードということになるようです。
結論
Pythonの内包表記は、コードを簡潔に書くための強力なツールです。しかし、複雑な内包表記はコードを読みにくくする可能性もあるので、適切なバランスを見つけることが重要です。一行の内包表記が長くなりすぎる場合や、多くの条件やループを含む場合は、通常のループ構造に戻すことを検討してみてください。
また、内包表記はパフォーマンス面でも優れています。通常のループ文に比べて内包表記は高速で動作するため、大量のデータを処理する際には特に有効です。
しかし、内包表記が新しく学ぶ概念である場合、まずは基本的な使い方から始め、徐々に複雑な表現に進んでいくことをお勧めします。Pythonの内包表記は、その柔軟性と強力さから、あなたのコーディングスキルに新たな次元を加えることでしょう。
Pythonの内包表記は、一見すると少々難解に見えるかもしれませんが、慣れてくるとその威力と便利さに驚くことでしょう。一歩ずつ進んで、この強力な機能をマスターしましょう。
以上が、Pythonの内包表記の基本的な使い方とその応用についての解説です。この記事がPythonの内包表記を理解し、活用する一助となれば幸いです。

参考サイト












コメント